超越Claude Mythos和GPT-5.5!斯坦福Agent验证框架拿下SOTA,Transformer作者转发
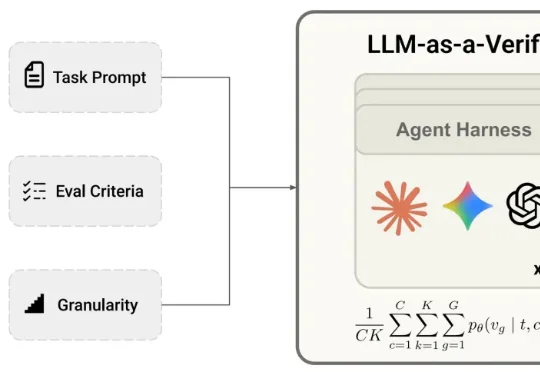
超越Claude Mythos和GPT-5.5!斯坦福Agent验证框架拿下SOTA,Transformer作者转发Transformer论文作者Lukasz Kaiser以及GAN作者Bing Xu转发关注了一项工作——LLM-as-a-Verifier验证框架,该方法是一种通用的验证机制,可与任意Agent Harness和模型结合。
来自主题: AI技术研报
8837 点击 2026-04-27 15:18